The following posting introduces recent work on exploring Spatial Cloud Computing and Big Geo-Data Analytics in GIScience research by our grad student Song Gao and his advisor Krzysztof Janowicz and colleagues:
The widespread use of location-awareness technologies and social media has enhanced the capability to collect large-scale spatio-temporal-semantic data for analyzing the world. At the same time, the scalable cloud computing platforms have made strong progress, enabling the implementation of big data management and knowledge discovery techniques that work on Terrabytes or Petabytes of data. In addition, it is now more convenient for researchers to utilize these cloud computing resources with the availability of low-cost, on-demand Web services of the Amazon elastic computing cloud (AWS EC2) and Amazon simple storage service (Amazon S3). In the GIScience community, spatial cloud computing has attracted increasing attention as a way of solving data-intensive, computing-intensive, or access-intensive geospatial scientific problems. There are increasing opportunities to collect and combine large volumes of geospatial data from a variety of agencies and from different volunteered geographic information (VGI) sources to facilitate scientific research and decision-making. However, two issues should be considered because of the efficiency and quality concerns. Firstly, the mining, harvesting, and geoprocessing of Big Geo-Data are computationally intensive, especially for geometry-related operations; thus, one question is how to integrate high performance computing solutions with advanced GIS functionality to achieve the goals. Secondly, the problems of heterogeneity and incompatibility in geospatial data affect the conflation process; thus, another question is how to optimize the feature matching procedure, which is one of the most challenging components in geospatial data conflation.
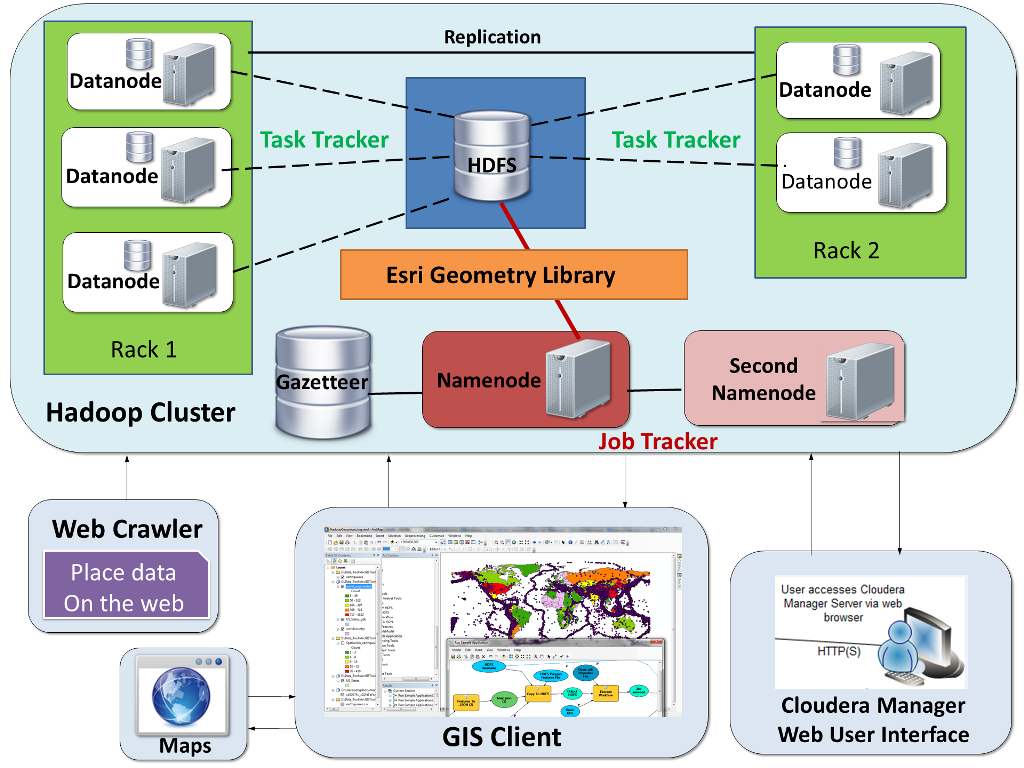
There are many Big Data analytics platforms and database systems emerging in the new era, such as Teradata data warehousing platform, MongoDB No-SQL database, IBM InfoSphere, HP Vertica, Red Hat ClusterFS, and Apache Hadoop-based systems like Cloudera and Splunk Hunk. They can be classified into two categories: (1) the massively parallel processing data warehousing systems like Teradata that are designed for holding large-scale structured data and support SQL queries; and (2) the distributed file systems like Apache Hadoop. The advantages of Hadoop-based systems mainly lie in their high flexibility, scalability, low-cost, and reliability for managing and efficiently processing a large volume of structured and unstructured datasets, as well as providing job schedules for balancing data, resources, and task loads. However, raw Hadoop-based systems usually lack powerful spatial analysis, statistics, and geovisualization tools.
In 2013 April, thanks to an introduction by Professor Michael F. Goodchild who is a member of Song’s advisory committee, Song had a meeting and continuous discussions with Esri’s Hadoop Team members, including Mausour Raad, Michael Park, and Marwa Mabrouk. In the following weeks, Song implemented a scalable spatial cloud computing platform based on Hadoop with the integration of timely released Esri GIS Tools for Hadoop for processing and analyzing Big Geo-Data. Such a geoprocessing-enabled Hadoop platform (GPHadoop) can benefit from both high-performance computing capacity and spatial analysis for processing spatial big data.
Later on, they applied the novel platform in the gazetteer research and geospatial data conflation work. Their work is now published online in the journal Computers, Environment and Urban Systems. Abstract:
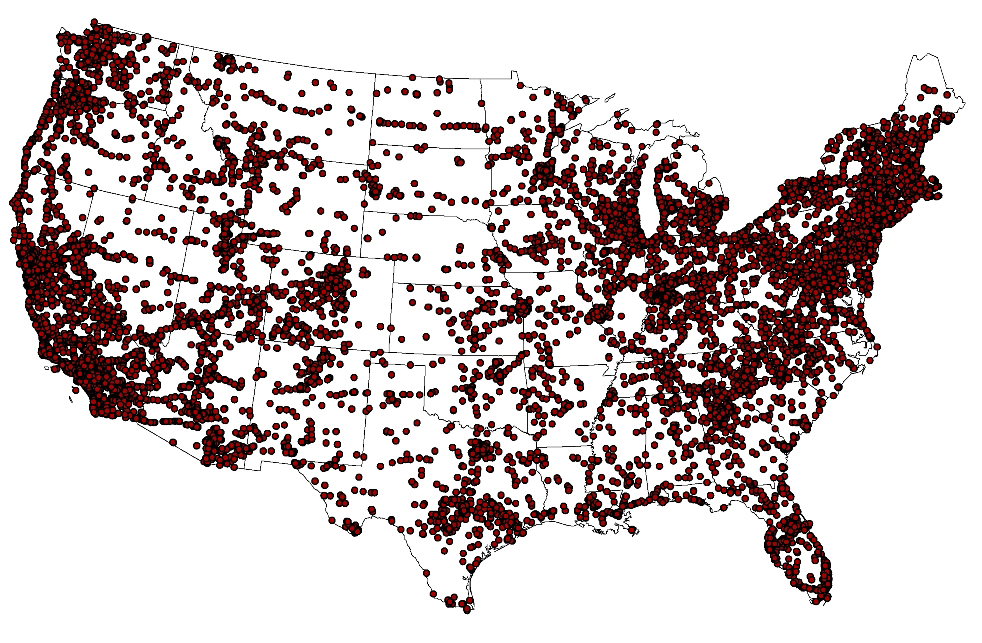
“Traditional gazetteers are built and maintained by authoritative mapping agencies. In the age of Big Data, it is possible to construct gazetteers in a data-driven approach by mining rich volunteered geographic information (VGI) from the Web. In this research, we build a scalable distributed platform and a high-performance geoprocessing workflow based on the Hadoop ecosystem to harvest crowd-sourced gazetteer entries. Using experiments based on geotagged datasets in Flickr, we find that the MapReduce-based workflow running on the spatially enabled Hadoop cluster can reduce the processing time compared with traditional desktop-based operations by an order of magnitude. We demonstrate how to use such a novel spatial-computing infrastructure to facilitate gazetteer research. In addition, we introduce a provenance-based trust model for quality assurance. This work offers new insights on enriching future gazetteers with the use of Hadoop clusters, and makes contributions in connecting GIS to the cloud computing environment for the next frontier of Big Geo-Data analytics.”
In addition, they have been developing an application of GPHadoop to parallelize an original algorithm of optimized linear feature matching for geospatial data conflation proposed by Linna Li and Mike Goodchild (2011) (An optimization model for linear feature matching in geographical data conflation. International Journal of Image and Data Fusion 2(4): 309–328). Using the divide and conquer strategy, it can process this algorithm in a parallel-sweeping manner on GPHadoop to improve the conflation efficiency. This procedure might be beneficial to conflating large volume of linear feature datasets provided by different government agencies such as US Census TIGER/Line and US Department of Transportation NTAD, or geospatial data downloaded from VGI sources.
Check out Song’s lighting talk at the CyberGIS’13 AHM for more details, and see his following references:
- Song Gao, Linna Li, Wenwen Li, Krzysztof Janowicz, Yue Zhang. (2014) “Constructing Gazetteers from Volunteered Big Geo-Data based on Hadoop”. Computers, Environment and Urban Systems. In Press.
- Song Gao. “A Hadoop-based GeoProcessing Platform for Big Geo-Data Analysis”. In 2013 NGA Academic Research Program Symposium and Workshops, Sept. 10-12, 2013, Washington D.C., USA.
- Song Gao, Linna Li, Michael F. Goodchild. “A Scalable Geoprocessing Workflow for Big Geo-Data Analysis and Optimized Geospatial Feature Conflation based on Hadoop”. In NSF CyberGIS AHM’13, Sept. 15-17, 2013, Seattle, WA, USA.